
As I was browsing through the internet on the last days of December, I came across a Java challenge from Gunnar Morling. I followed it from start to finish and witnessed in real-time the attention that it gathered, as well as the many innovative solutions that various programmers came up with. I'm writing this to share the neat tricks I saw, the awesome stuff I learned along the way, and what I'm hoping we'll see in challenges down the road.
Write a Java program for retrieving temperature measurement values from a text file and calculating the min, mean, and max temperature per weather station. There’s just one caveat: the file has 1,000,000,000 rows
The input file consisted of 1 billion temperature values from up to 10000 unique cities that need to be aggregated. The output was supposed to print the A-Z list of cities together with the minimum, maximum and average temperature values.
There were also some input data assumptions, such as the file encoding should be UTF-8, the city name can have between 1-100 bytes, be arbitrary, and cannot contain “;” or “\n”. The temperature must have a fractional digit.
For the contest to be fair, a few rules* were put in place:
* To read all the rules, do check Gunnar Morling’s github or the initial blog post.
I was genuinely astonished to observe a Java programming challenge capturing such an immense level of interest and participation from the community. It ended up becoming a learning experience for anyone interested in Java, with crazy and unexpected solutions that people came up with. Bright minds working at top companies, such as Oracle, Amazon, QuestDB, Hazelcast, plus a bunch of JDK committers and more, have also joined the challenge.
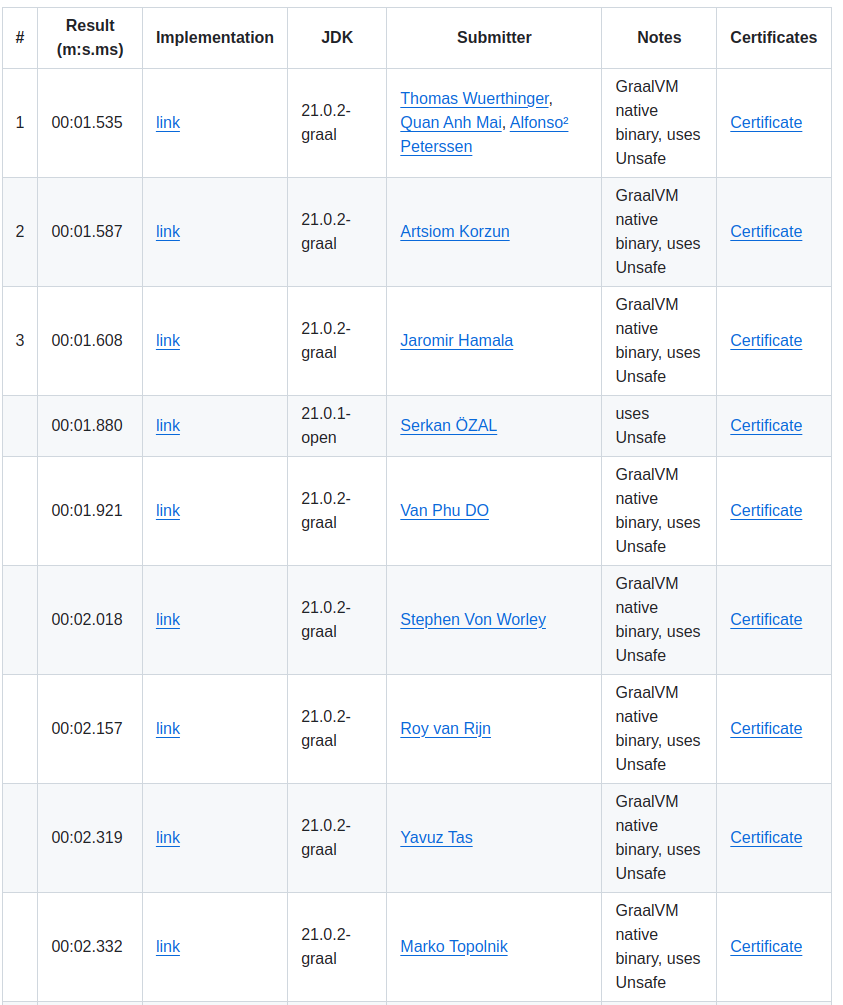
Over 500 pull requests have been submitted to Github, each optimizing different aspects of the problem, with the top solution going down to an incredible time of 1:535 sec, that is two orders of magnitude faster than the baseline set by Gunnar, which was 4:49 min.
This challenge managed to bring together the Java community in a quest for optimization. Gunnar wanted to show how fast Java has actually become, so he challenged the developers to explore high-performance programming techniques, new APIs, as well as various Java distributions and their capabilities.
The baseline implementation time of almost 5 mins was quickly brought down to 2 minutes by making the java stream parallel in the very first pull request submitted. This was a sensible thing to do.
The next big improvement that followed up shortly was the using of memory mapped files and splitting it into chunks. Interestingly enough, the first solution split the file into 10MB chunks. Then, the majority of the contestants chose to split the big file into 8 segments - the number of cores used by the test machine, only for them to settle with 2MB chunks in the end as the fastest solution. Nobody seemed to know exactly why 2MB chunks performed best, however it was speculated it has something to do with the huge page size on the test machine - 2MB.
Another quick win for improving speed, which was fairly easy to implement from the beginning, was to prefer integer numbers for arithmetic operations since they are much faster than on floating points.
Then the crazy things started. There were some early attempts to use SIMD with the incubating Java Vector API. SIMD stands for Single Instruction Multiple Data and it is a parallelization technique for performing operations on an entire data array in a single CPU cycle, with hardware support. While everybody was anticipating this would produce great results, it wasn't widely adopted. Is it because of the lack of native support for the incubating API in GraalVM which the majority of top 10 solutions adopted ?
SWAR - SIMD within a register, on the other hand, was widely adopted for parsing. SWAR is the poor man's SIMD, a rather software oriented approach that is portable, flexible, but can perform parallel computation on a much limited data chunk - a register, remember?
The next step was resorting to branchless programming. It's a programming mindset that uses bit twiddling tricks in order to eliminate branches in the code. It seems that, when dealing with a synthetic data set to be processed, the CPU can have a lot of branch mispredictions which translate to a speed penalty for every row of data. And since we are dealing with 1 billion lines to process, this penalty is hugely amplified.
Not surprisingly, one of the most brilliant tricks I've seen in the challenge uses branchless parsing for parsing the temperature value into an int and was quickly picked up by other participants as it led to huge improvements in the speed. This code was not easy to understand so kudos to the pull request reviewers that encountered such code :).
The solutions were getting obscenely quick at resolving the challenge, however about 15% of the running time was spent by Linux kernel code unmapping the memory after the code was done. The process was not allowed to finish by the OS until the memory was unmapped and this was a single threaded painfully slow process that had nothing to do with the java implementations. So a very clever trick that solved the memory unmap bottleneck was to spawn a subprocess that does the whole job and produces the results. The main process listens at the standard output of the subprocess and when the results are available it is allowed to exit, while the subprocess remains busy in the background with the memory unmapping. Pretty cool, don’t you think? And Gunnar was nice enough to permit this because it eliminates the external influence from the equation.
Unsafe sounds really dangerous, right? Well, that's the name of a Java class that is really unsafe to use at home. Actually, the creators of the Java language tried so hard to not let people use it, that the only way to instantiate it is via reflection. sun.misc.Unsafe allows unrestricted, unchecked, direct memory access and you could really mess things up if you don't know what you're doing. On the other hand, Unsafe seemed perfect for the challenge because it can really speed the processing up. So participants slowly, reluctantly adopted it. They tried to get by without using it, however, the benefits were too high. So high that 14 out of top 15 solutions used it by the end. Coincidentally or not, during the challenge, sun.misc.Unsafe memory access methods were proposed for deprecation in https://openjdk.org/jeps/8323072. Funny, right?
Same can be said about the Java distribution used. While most of the solutions used openjdk in the beginning, by the end of the competition, the majority of them switched to Oracle GraalVM and only a select few finished the competition still using the open version. It seems like, even the most manually optimized code still benefits from the optimizations done by the GraalVM compiler. Moreover, 7 out of top 10 solutions switched to GraalVM native image in order to take advantage both of faster startup time and no JIT warm-up, but also from less variance in running times.
However, there have been some solutions that were pure high-level Java as well, no Unsafe, no native image, no bit twiddling tricks and still had an amazing under 10s execution.
I couldn’t help but notice the traction this competition got with people from other languages like C, C#, Go, Rust or Python or even some like QuestDB or Oracle. While there were several parallel competitions, it's challenging to draw direct comparisons to them because they did not operate under the same test and evaluation conditions as the Java one. This is precisely why, harboring a secret wish for the next Gunnar’s challenge, I find myself hoping it might extend its scope to involve other programming languages.
I believe this challenge was the perfect showcase of teamwork, demonstrating that more human brains working collaboratively can exceed any expectations. The fact that the contenders left "thank you-s” in their comments and added referrals to other people's ideas, was mostly unexpected and kept the 'ball rolling.' This raised the bar higher and higher, reaching last night the unbelievable time of 01:53 seconds. I truly believe this result couldn't have been achieved unless these conditions were fulfilled: collaboration, openness, and curiosity. All the commits that were under 3 seconds kept everyone stunned and in expectation: 'Will anyone manage to do it faster?' As Thomas Wuerthinger put it: when you think there’s nothing left to optimize… you just might be surprised! It was like watching the finals.
So, for all this show - thanks to the participants, thanks to the creator: thank you Gunnar Morling. Looking forward to seeing what you cook next.

Marius Staicu is an IT professional with over 17 years of experience, passionate about creating smart, scalable technology solutions that solve real-world problems. With expertise in areas like IoT, cloud computing, and software modernization, he has led projects handling massive amounts of data and ensuring smooth operations. He thrives on tackling complex technical challenges, fostering teamwork, and driving innovation forward.