Modular Platform for Data Analysis
Handle, process, and analyze vast amounts of data, in real-time or in batch, with KubeLake - the dynamic data platform.
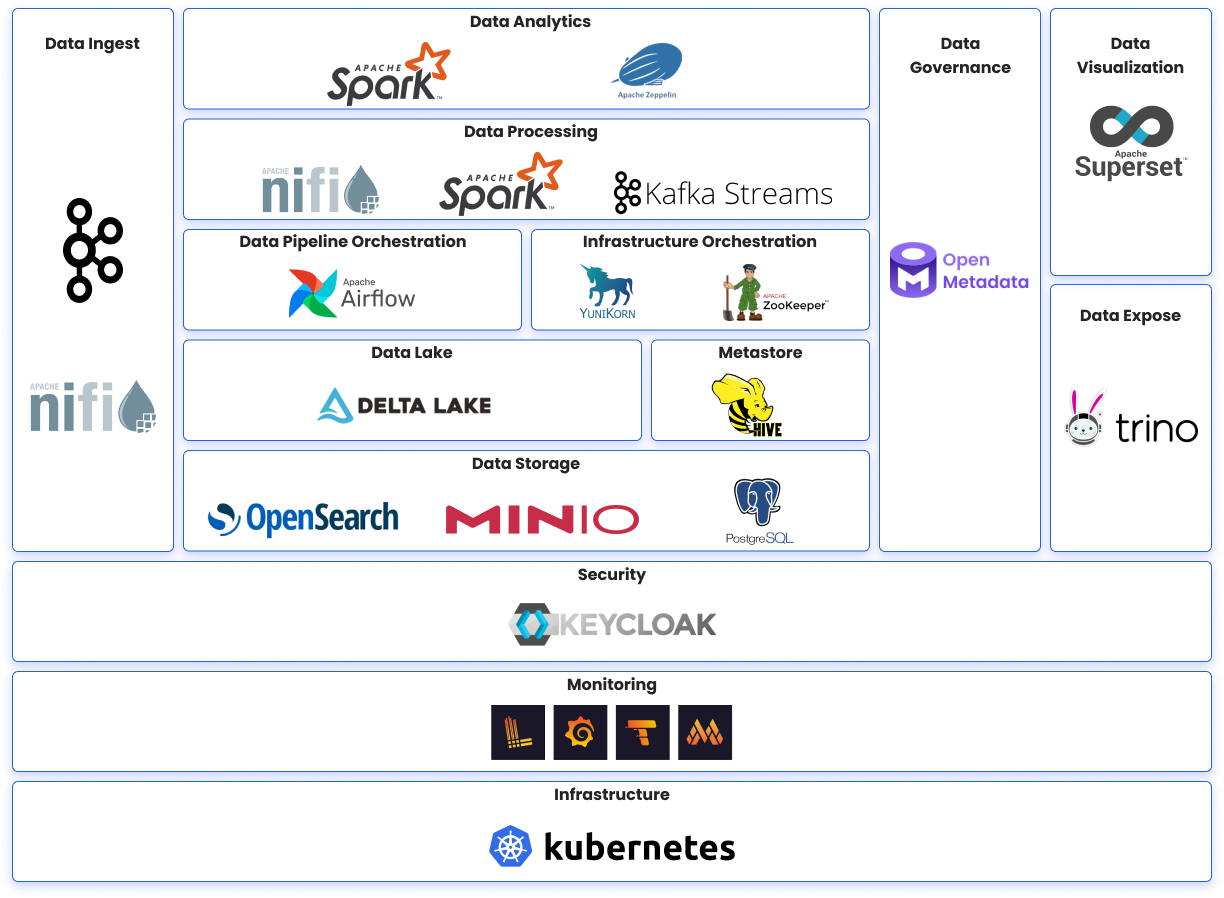
Designed with flexibility and scalability in mind, KubeLake can support any type of data architecture and use cases such as data warehouse, data lake, data mesh, operational data platform (ODP), customer data platform (CDP), or data integration platform.
By providing data acquisition, data storage, and data processing capabilities, KubeLake ensures seamless data integration, offering a single point of truth for your data, and a single point of contact for all your big data tools. Engineers can add and use various open-source big data tools to cater to your specific use case.
KubeLake is Kubernetes-native, allowing you to use the infrastructure of your choice, on-prem or in the cloud, to manage both data and apps, with multi-environment clusters, and separation of responsibilities.