
Nowadays, applications rarely operate alone - they need to communicate, share data, and collaborate with other systems to deliver comprehensive and efficient services. This has led to the development of various communication paradigms throughout the years, each designed to address specific integration needs, as well as various use cases. The most common integration options are file transfer, shared database, connectors, APIs, and messaging.
Choosing the right communication paradigm is essential for modern software architectures. In this article, we will focus on messaging and its subtypes (message queues and event streaming).
Message queuing and event streaming each have their strengths: message queuing is ideal for reliable, ordered message delivery and complex routing, while event streaming excels in high-throughput, low-latency data processing. However, they can also be combined to suit your unique use case. Let’s explore the distinct characteristics, advantages, and potential use cases for each of them in more detail.
The microservices architecture is a popular way to build large-scale, complex apps. They structure an application as a collection of loosely-coupled, independently deployable services, each handling a specific business function. This modular approach allows for better scalability, flexibility, and maintainability.
A critical aspect of microservices is how they integrate with each other. Ideally, communication between internal microservices must be as little as possible for increased efficiency.
There are two types of communication paradigms: synchronous and asynchronous.
Relying on synchronous HTTP connections between microservices, like in the long request/response cycles shown in image below, makes the microservices less independent and slows down performance. Synchronous communication between microservices forms a "chain" of requests to fulfill a client's request, and is considered an anti-pattern. If one service in the chain has problems, it affects the whole system's performance.
A good practice is to adopt asynchronous communication (pictured below), which allows microservices to interact using asynchronous messages or HTTP polling, so that the client request is served right away.
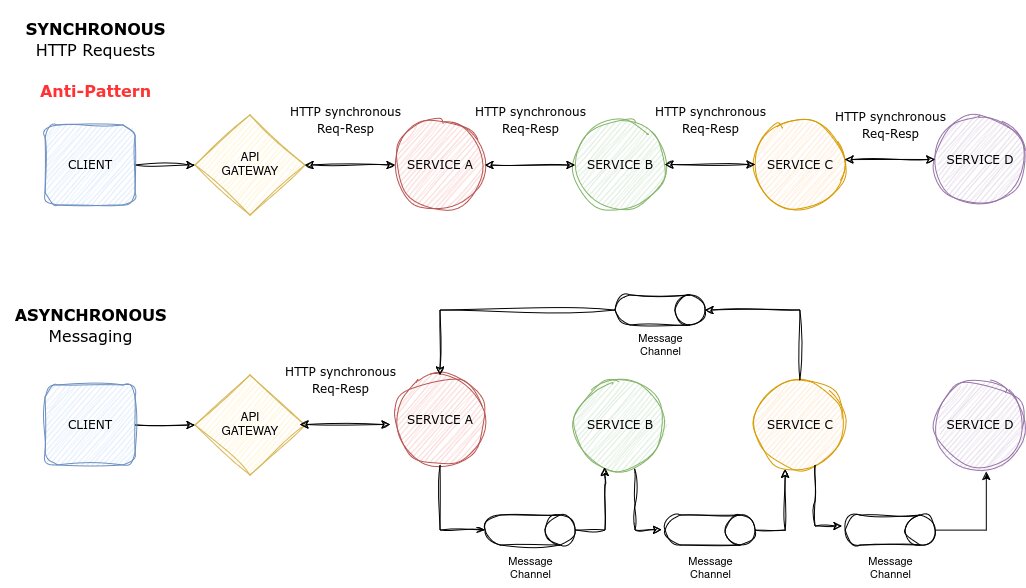
Messaging is the process of sending and receiving data asynchronously between different parts of an application or between different services, usually via an intermediate component called broker.
concept of messaging dates back to the 1970s and 1980s with the advent of systems like IBM's Customer Information Control System (CICS) and MQSeries (later IBM MQ), which facilitated asynchronous communication between systems. In 1998, the Java Message Service (JMS) was introduced as part of the Java 2 Platform, Enterprise Edition (J2EE). JMS provided a standardized API for Java applications to create, send, receive, and read messages from message-oriented middleware systems. While JMS was beneficial for Java applications, it was not designed for interoperability with non-Java applications.
In the following years, protocols such as AMQP, MQTT and STOMP were developed to provide more flexible and lightweight options, incorporating similar concepts from JMS. Brokers like ActiveMQ and RabbitMQ were created to implement these protocols. In 2011, LinkedIn developed Apache Kafka, an event streaming platform which has become one of the most well-known brokers in recent years.
A message is a generic term used to describe a packet of data sent from one component to another and it’s usually composed of two parts, a header and a payload. There are different types of messages, including:
When one application needs to send data, it doesn't simply throw the data into the messaging system. Instead, it sends the data to a specific Message Channel. Similarly, an application that is waiting to receive data doesn't just randomly grab data from the messaging system. It retrieves data from a specific Message Channel.
The sending application (producer) doesn't necessarily need to know which particular application will ultimately receive the data. However, what is certain is that the application that receives the data (consumer) will find it relevant and useful.
Now let’s see which message channel patterns are most commonly used.
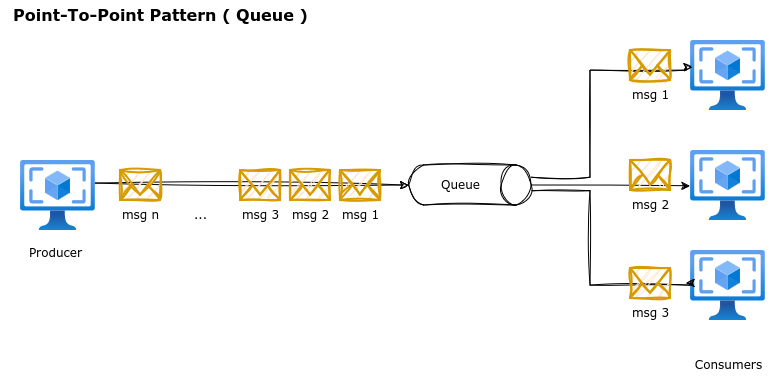
The point-to-point messaging pattern involves sending messages from a producer to a specific consumer via a queue, ensuring that each message is consumed by only one receiver.
Properties:
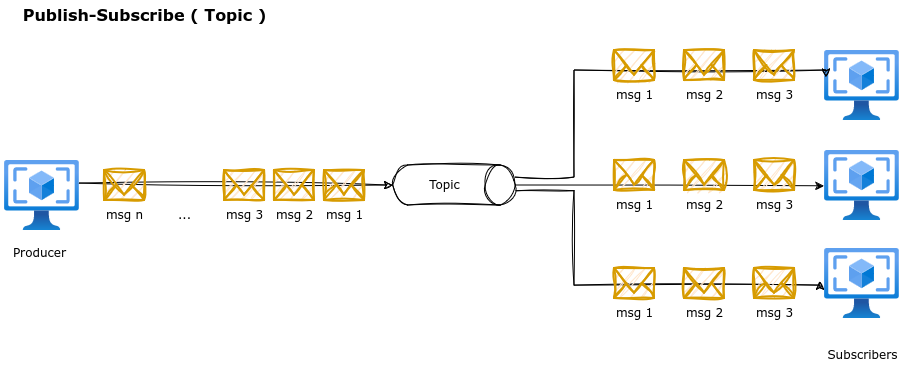
The publish-subscribe messaging pattern involves sending messages from a publisher to multiple subscribers through topics or channels, allowing messages to be received by all interested subscribers.
Properties:
Now that we have explored some general aspects of messaging, let's take a look at the most common messaging tools, along with an overview of their differences in terms of types, protocols, and the patterns they implement.
|
Technology |
Type |
Point-To-Point (Queue) |
Publish-Subscribe (Topics) |
Protocols |
|
Apache ActiveMQ |
Message Broker |
? |
? |
AMQP, MQTT, OpenWire (native), STOMP etc. |
|
Apache RabbitMQ |
Message Broker |
? |
? |
AMQP, MQTT, STOMP etc. |
|
Eclipse Mosquitto |
MQTT Broker |
? |
? |
MQTT |
|
HiveMQ |
MQTT Broker |
? |
? |
MQTT |
|
Apache Kafka |
Event Streaming |
? |
? |
custom binary protocol |
|
Amazon SQS |
Message Queue |
? |
? |
HTTP/HTTPS, AWS SDK |
|
Amazon SNS |
Notification Service |
? |
? |
HTTP/HTTPS, AWS SDK |
|
Google Cloud Pub/Sub |
Event Streaming |
? |
? |
HTTP/HTTPS, gRPC |
|
Azure Service Bus |
Message Broker |
? |
? |
AMQP, HTTP/HTTPS |
|
IBM MQ |
Message Broker |
? |
? |
MQTT, AMQP, IBM MQ protocol |
|
Redis Pub/Sub |
Pub/Sub System |
? |
? |
Redis protocol |
|
Azure EventHub |
Event Streaming |
? |
? |
AMQP, HTTP/HTTPS, Kafka protocol |
We can see that many of these technologies share similarities and common features. Some implement only queues, others only topics, and some support both. Many offer the flexibility of multiple protocols, while others rely on their own custom protocols.
Additionally, they can be categorized into several types:
The market offers plenty of solutions, all with different features and strengths. This brings us to a highly debated question in the software engineering community: which one should I use?
The answer depends on various factors, such as specific use cases, performance requirements, scalability needs, and integration capabilities. By understanding the architectural distinctions and how they align with your project's demands, you can make an informed choice that best suits your needs.
A common dilemma arises when deciding whether to use a traditional message broker or an event streaming platform so let’s take a closer look at them.
We will analyze and see the main differences between Traditional Message Brokers and Event Streaming Platforms. For this, let’s compare the internal architectures of two of the most used message brokers in the industry: RabbitMQ (Traditional Message Broker) and Apache Kafka (Event Streaming Platform).
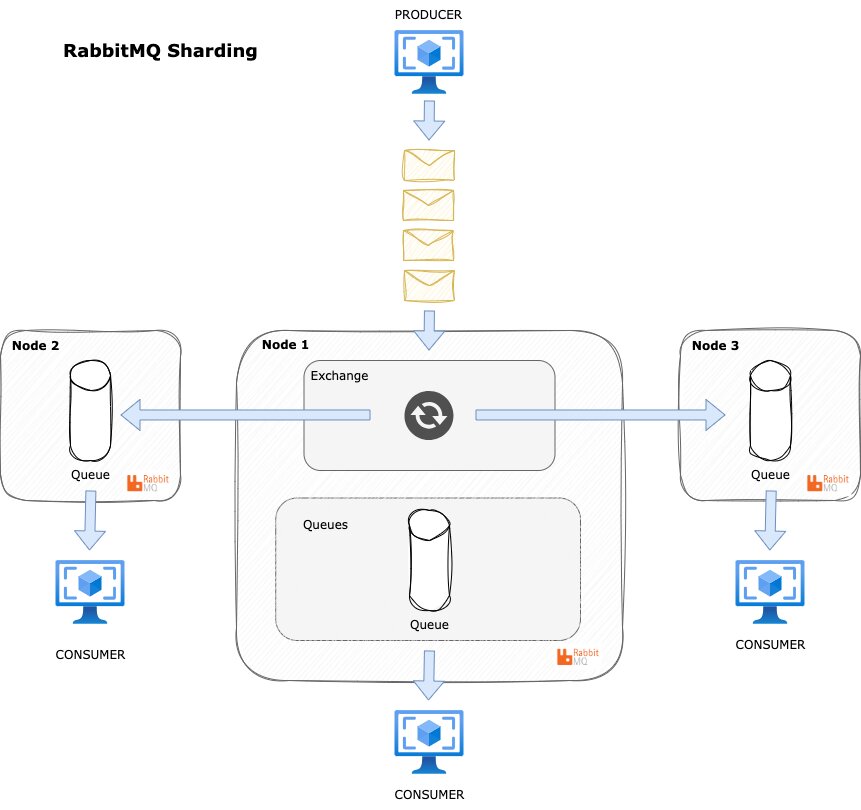
At its core, RabbitMQ uses exchanges to route messages from producers to queues, which then store the messages until consumers retrieve them. There are various types of exchanges, such as direct, topic, fanout, and headers, each defining different routing rules.
Producers send messages to exchanges, which then distribute the messages to queues based on the binding rules set between exchanges and queues. Consumers connect to queues to receive and process messages. This interaction happens over TCP connections, which can support multiple virtual connections known as channels.
RabbitMQ supports clustering, allowing multiple nodes to work together for high availability and scalability.
The architecture of a streaming platform, such as Kafka, is completely different. Kafka is built around the concept of a distributed, partitioned, and replicated log service. Producers send records (messages) to topics, which are split into partitions. Each partition is an ordered, immutable sequence of records, and new records are appended to the end of the partition. This partitioning allows Kafka to scale horizontally, as different partitions can be distributed across multiple Kafka brokers, enabling parallel processing and high throughput.
Kafka brokers are the servers that store the data and serve client requests. Each broker handles a subset of the partitions for each topic, and partitions are replicated across multiple brokers to ensure fault tolerance and high availability. If a broker fails, another broker that holds a replica of the partition can take over, ensuring that data is not lost and processing continues seamlessly.
Consumers in Kafka read records from partitions. Kafka employs a consumer group mechanism, where each consumer in a group reads from a subset of partitions, allowing for load balancing and coordinated consumption of data. This ensures that each record is processed by only one consumer within the group, but the work is distributed among all consumers in the group.
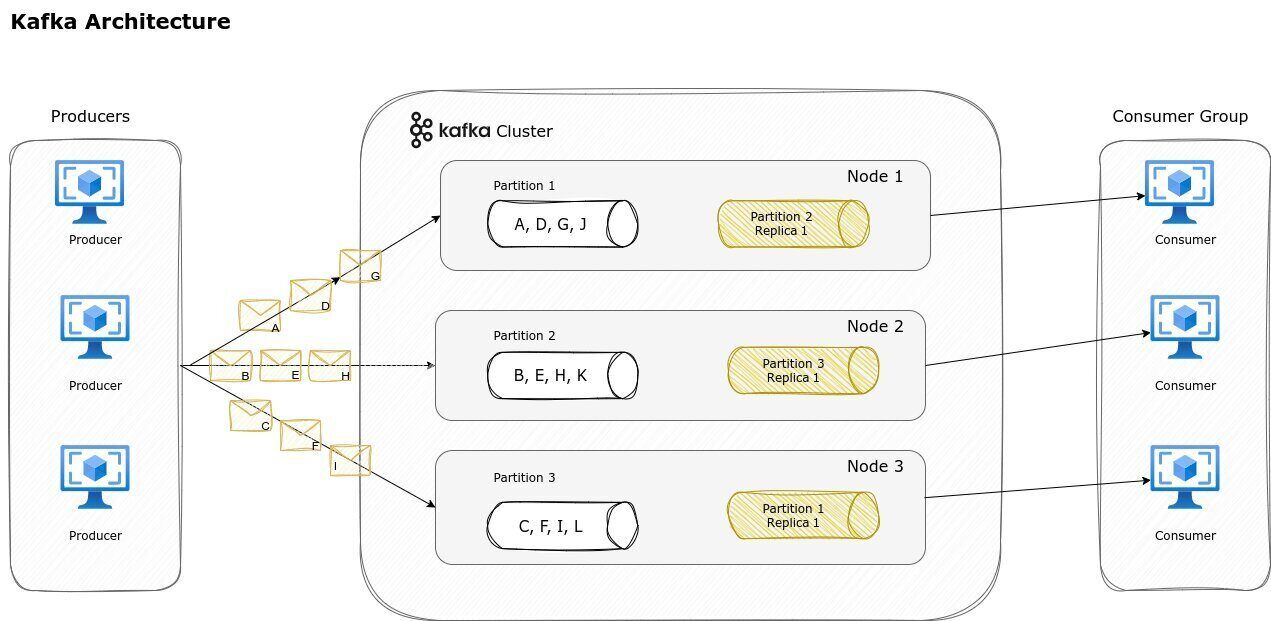
For a better understanding of Kafka, check out our Intro to Kafka article, which provides a great starting point.
Let's take a closer look at the key differences and similarities between Apache Kafka and RabbitMQ:
|
Feature |
Apache Kafka |
RabbitMQ |
|
Protocols |
Custom binary protocol |
AMQP, MQTT, STOMP etc. |
|
Message Ordering |
Guaranteed within a partition |
Guaranteed within a queue |
|
Performance |
Very high throughput, optimized for large-scale streaming |
High throughput, optimized for individual message delivery |
|
Delivery Semantics |
At least once (default), at most once, exactly once (with configurations) |
At least once |
|
Dead Letter Queues |
Supported via additional configurations or third-party tools (Kafka Connect) |
Natively supported |
|
Message Consumption (Push/Pull) |
Pull-based consumption |
Push-based consumption |
|
Scalability |
Horizontally scalable with partitions |
Horizontally scalable with queues and clustering |
|
Message Retention |
Configurable retention periods, supports long-term storage |
Messages are deleted once consumed unless configured otherwise |
|
Persistence |
Log-based storage, highly durable |
Durable queues and messages with configurations |
|
Consumer Groups |
Yes, with automatic load balancing across consumers in a group |
Basic load balancing through competing consumers |
|
Replication |
Configurable replication factor per topic |
Mirrored queues with manual configurations |
|
Built-In Stream Processing |
Yes ( Kafka Streams ) |
No |
Traditional Message brokers are a good fit for:
Event streaming platforms are well-suited for the following use cases:
Communication paradigms can make or break your applications so choosing the right communication paradigm is crucial. While message queuing and event streaming each have their strengths, keep in mind that these technologies can also overlap and/or complement each other. For instance, RabbitMQ can handle immediate task distribution while Kafka manages real-time data analytics.
Understanding the specific needs of your application will guide you in selecting the right tool or combination of tools to build a robust and scalable system, and an architecture that meets your operational and performance requirements effectively.

Mircea Malaescu is an Azure-certified Data Engineer with over six years of experience in big data technologies, including Hadoop, Cassandra, NiFi, Kafka, and Spark. He has extensive experience in DevOps engineering practices and has handled projects in the exciting retail and automotive industries. Mircea is currently working on a streaming project based on Kafka and Azure.