
Bucketing in Spark is a way to organize data in the storage system in a particular way so it can be leveraged in subsequent queries which can become more efficient.
With bucketing, we can shuffle the data in advance and save it in this pre-shuffled state. After reading the data back from the storage system, Spark will be aware of this distribution and will not have to shuffle it again.
The problem appears when we receive some error in our Spark job . This error occurred because somewhere in this job we did not take into account the shuffle which could occur and how big it can be. So we tried to find a solution to optimize / eliminate this shuffle.
User class threw exception: org.apache.spark.SparkException: Job aborted due to stage failure: ShuffleMapStage 5 (save at KafkaWriter.scala:12) has failed the maximum allowable number of times: 4. Most recent failure reason: org.apache.spark.shuffle.FetchFailedException: Failure while fetching StreamChunkId{streamId=935263887140, chunkIndex=0}
This job was configured to run with 1GB driver memory and 2GB executor memory, 4 executors and 4 executor cores. To run the job again we increase the job parameters to 2GB driver memory and 3GB executor memory. But this was not the solution we wanted.
The Spark job script was to join some data read from Cassandra with a snapshot from Hive. Although the data was collected from distributed systems, in this case we did not use this capability, we read all the data and then we processed them.
def apply(cassandraDF: DataFrame, hiveDF: DataFrame): DataFrame = {
cassandraDF.join(hiveDF, joinExpression, "full")
}
We reviewed this Spark job and discovered that we have a very big shuffle.

Shuffle is an expensive operation as it involves moving data across the nodes in your cluster, which involves network and disk I/O. It is always a good idea to reduce the amount of data that needs to be shuffled.
Examining our execution plan, we notice that Spark employed a SortMergeJoin , as expected, to join the two DataFrames. The Exchange operation is the shuffle of the DataFrames on each executor. The Exchange is expensive and requires partitions to be shuffled across the network between executors.
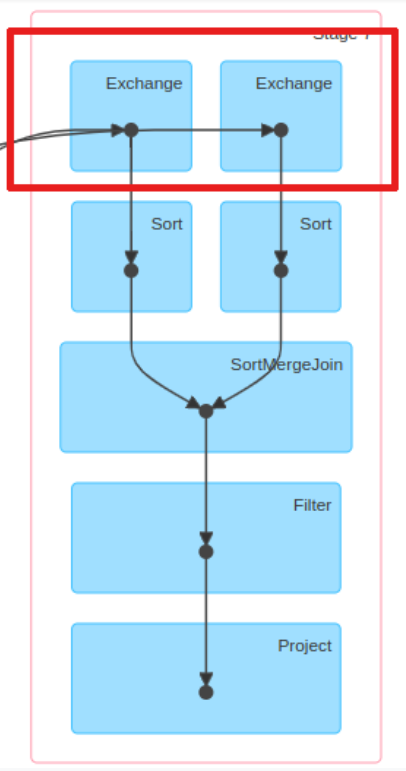
As you can see, each branch of the join contains an Exchange operator that represents the shuffle. So our goal was to eliminate the Exchange step from this scheme by creating partitioned buckets. Presorting and reorganizing data in this way boosts performance, as it allows us to skip the expensive Exchange operation and go straight to SortMergeJoin .
In Spark API there is a function DataFrameWriter.bucketBy(numBuckets, col, *cols) that can be used to make the data bucketed.
This function is applicable for file-based data sources in combination with DataFrameWriter.saveAsTable(). Calling saveAsTable will make sure the metadata is saved in the metastore and Spark can pick the information from there when the table is accessed.
The first argument of the bucketBy is the number of buckets that should be created. Choosing the correct number might be tricky and it is good to consider the overall size of the dataset and the number and size of the created files.
df.write
.mode(saving_mode) # append/overwrite
.bucketBy(n, field1, field2, ...)
.sortBy(field1, field2, ...)
.option("path", output_path)
.saveAsTable(table_name)
Spark Bucketing has its own limitations and we need to be very cautious when we create the bucketed tables and when we join them together.
To optimize the join and make use of bucketing in Spark we need to be sure of the below:
In the following code snippet we bucket by the same columns on which we’ll join, and save the buckets as Spark managed tables in Parquet format:
def apply(cassandraDF: DataFrame, hiveDF: DataFrame): DataFrame = {
…………….
cassandraDF.write.format("parquet")
.mode(SaveMode.Overwrite)
.bucketBy(bucketNumber, firstBucketColumn, lastBucketColumns)
.saveAsTable('cassandraBucketTable')
val cassandraBucketDF = sparkSession.table('cassandraBucketTable')
hiveDF.write.format("parquet")
.mode(SaveMode.Overwrite)
.bucketBy(bucketNumber, firstBucketColumn, lastBucketColumns)
.saveAsTable('hiveBucketTable')
val hiveBucketDF = sparkSession.table('hiveBucketTable')
cassandraBucketDF.join(hiveBucketDF, joinExpression, "full")
}
Looking at the Spark UI, we can see that the Exchange operator is no longer present in the plan and the job did not have to shuffle the data because both the tables are already partitioned.

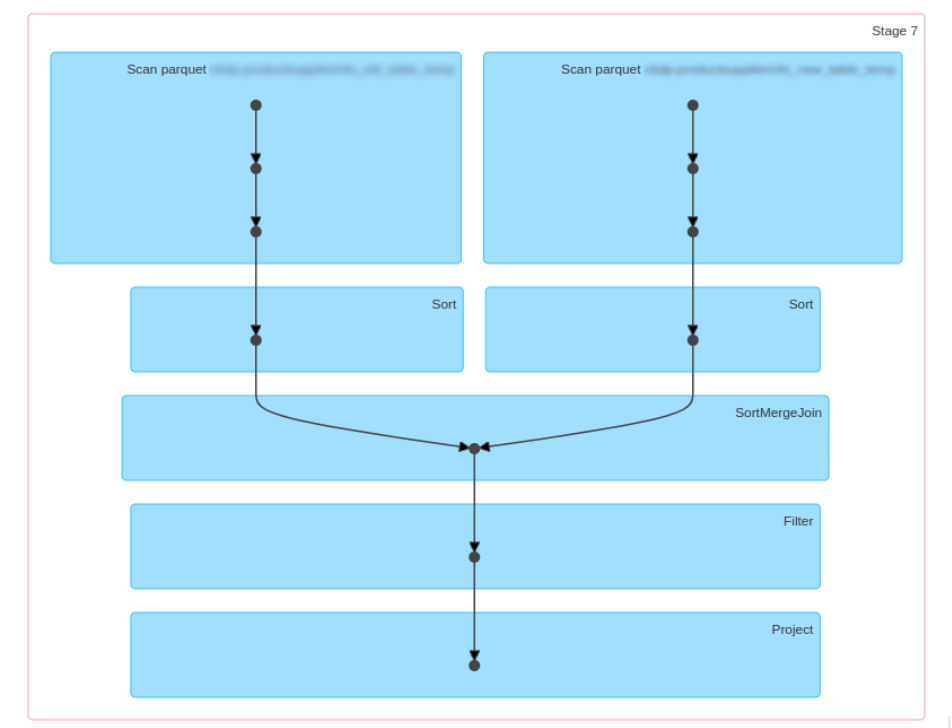
The new job was run with the initial configuration. We even tried to lower the memory configuration values and the job worked fine, but the running time has increased compared to the initial values.
The increase in execution time was due to the IO operations like writing and reading parquet files.
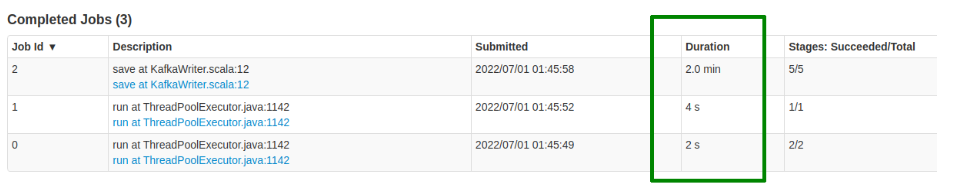
The times for the job without any modification was:
and for the new jobs we get the values:
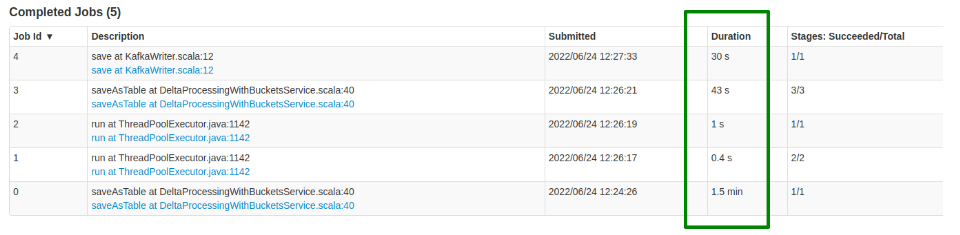
In this case we decided to try the bucketing solution as we did not want to increase the resources allocated to the job.
The tables in the data lake are usually prepared by data engineers. They need to consider how the data will be used and prepare it so it serves typical use-cases of the data users. Bucketing is one of the techniques that need to be considered similarly to partitioning which is another way to organize data in the file system.
In this example we saw how bucketing helps to avoid shuffle in queries with joins and aggregations.
Florentina Bobocescu is a senior developer who has more than 10 years extensive experience in Software Development. She is always looking to enhance her area of knowledge, learn new technologies, and take on new challenges. Lately, Florentina has focused on Big Data projects experimenting with new technologies and frameworks, being also a Microsoft Certified: Azure Data Engineer Associate.
Reference: