
Almost all the online shops or content-based sites use Recommendation Systems. The purpose is to improve customer experience, but also to make all the products (content) more visible. Recommendation Systems don’t always require huge resources and lots of software tools. We will show in this article how a Collaborative Filtering Recommendation System can be built using Apache SOLR.
Product (content) recommendations can be of many types. Our main focus in this article is how to recommend products that are “frequently bought together”. This means that a current customer, viewing a product, will receive a list of products that were bought together with that product. There is, however, a trick here: not all products “bought together” are good recommendation candidates. Think of a “grocery bag” in a supermarket. It is “frequently bought together” with anything, but recommending it is useless. So, a “Term Frequency / Inverse Document Frequency ” (TF / IDF) formula will be used in order to correctly rank the recommendation candidates. After applying this formula, the recommendations are the top products ranked by score.
Apache SOLR is “the popular, blazing-fast, open-source enterprise search platform built on Apache Lucene”, as the official page states. Lots of online shops or content-based sites use SOLR for search/faceting. It is a scalable tool, that developed a lot in the last few years. So why use it only for search, when it can be used also as a powerful recommender system? If the online shop (content site) already uses SOLR for search, using the same tool for recommendations comes as a natural step. Streaming Expressions contain functions that can be used for recommendations.
The “frequently bought together” algorithm will analyze at runtime the existing shopping carts and extract the products that were bought together with the “seed” product. It will then sort them by occurrence number and apply a TF / IDF formula to calculate relevance score.
The TF / IDF formula will help by decreasing the score of the products occurring too often.
TF = term frequency -> higher for products appearing together with the “seed” product
IDF = inverse document frequency -> lower for products appearing together will all other products
The data set used in this article has:
The data contains:
These 6 products are contained among others:
- grocery_bag: ![]()
- saussage_type_1: ![]()
- saussage_type_2: ![]()
- mustard: ![]()
- meat: ![]()
There are some carts with this content (among other products):
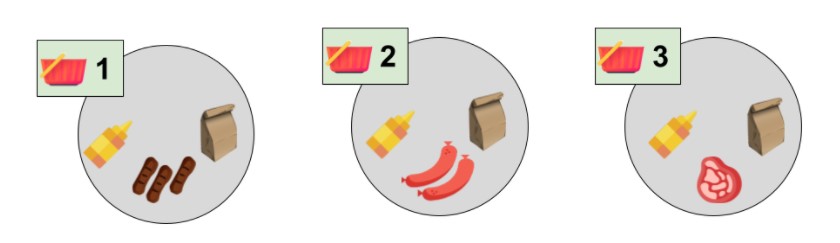
What should the Recommendation System recommend to a user currently viewing the mustard product (our “seed” product)? According to the history shopping carts, the recommendations would be:
and do not recommend: grocery_bag (as being irrelevant)
Desired result:

1) Extract a subset of the entry data (shopping carts)
We randomly extract 100 shopping carts that contain our “seed” product = mustard.
random(demo_orders, q="item_id:mustard", fl="order_id", rows="100")
The result of this step includes the following shopping carts:
{
"order_id": "70"
},
{
"order_id": "44"
},
{
"order_id": "1"
},
...
2) Gather the recommendations candidates out of the products bought together with our “seed” product
For this step, we will represent the data as a shopping cart -> product graph:
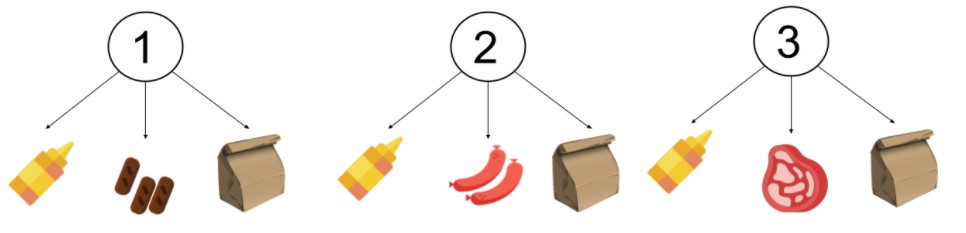
And we will gather all the items contained in all the orders that contain “mustard”.
gatherNodes(demo_orders,
random(demo_orders, q="item_id:mustard", fl="order_id", rows="100"),
walk="order_id->order_id",
fq="-item_id:mustard",
gather="item_id",
count(*)
)
The result includes the following products:
{
"node": "saussages_type_1",
"count(*)": 22,
"collection": "demo_orders",
"field": "item_id",
"level": 1
},
{
"node": "saussages_type_2",
"count(*)": 22,
"collection": "demo_orders",
"field": "item_id",
"level": 1
},
...
3) Get a list of the top 10 products ordered by how often they appear in the previous list
top(n="10", sort="count(*) desc",
gatherNodes(demo_orders,
random(demo_orders, q="item_id:mustard", fl="order_id", rows="100"),
walk="order_id->order_id",
fq="-item_id:mustard",
gather="item_id",
count(*)))
The result includes:
{
"node": "grocery_bag",
"count(*)": 66,
"collection": "demo_orders",
"field": "item_id",
"level": 1
},
{
"node": "saussages_type_1",
"count(*)": 22,
"collection": "demo_orders",
"field": "item_id",
"level": 1
}
4) Apply a TF/IDF formula in order to calculate the score
TF/IDF = Term Frequency / Inverse Document Frequency
scoreNodes(top(n="10",
sort="count(*) desc",
gatherNodes(demo_orders,
random(demo_orders, q="item_id:mustard", fl="order_id", rows="100"),
walk="order_id->order_id",
fq="-item_id:mustard",
gather="item_id",
count(*))))
The results include:
{
"node": "saussages_type_1",
"nodeScore": 20.32023,
"field": "item_id",
"numDocs": 1214,
"level": 1,
"count(*)": 22,
"collection": "demo_orders",
"docFreq": 22
},
{
"node": "grocery_bag",
"nodeScore": 16.909515,
"field": "item_id",
"numDocs": 1214,
"level": 1,
"count(*)": 66,
"collection": "demo_orders",
"docFreq": 126
}
5) Take the first 3 products, ordered by score. These are the recommended products.
top(n="3",
sort="nodeScore desc",
scoreNodes(top(n="10",
sort="count(*) desc",
gatherNodes(demo_orders,
random(demo_orders, q="item_id:mustard", fl="order_id", rows="100"),
walk="order_id->order_id",
fq="-item_id:mustard",
gather="item_id",
count(*)))))
The results are:
|
Product |
Score |
|
meat |
20.32023 |
|
saussages_type_1 |
20.32023 |
|
saussages_type_2 |
20.32023 |
Use the files from https://github.com/oanabrezai/relatedItemsSolr.
1) Create the SOLR configuration template
/[PATH]/solr-8.8.0/bin/solr zk upconfig -z 127.0.0.1:9983 -n order_template -d [PATH]/orders/
2) Create a collection
curl "http://localhost:8983/solr/admin/collections?action=CREATE&name=demo_orders&numShards=1&replicationFactor=1&collection.configName=order_template"
3) Populate the collection
http://localhost:8983/solr/demo_orders/update/csv?commit=true&stream.file=[PATH]/orders.csv&stream.contentType=text/plain;charset=utf-8&separator=,
4) Run the Streaming Expressions in SOLR Console
A streaming expression example in SOLR Console:
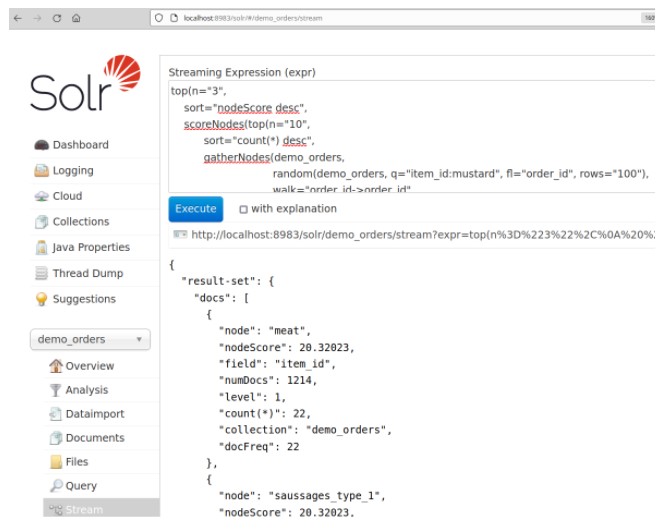
We showed how a “frequently bought together” recommendation can be built using Apache SOLR with Streaming Expressions.
PROS
CONS
We will present how to implement this algorithm in JAVA in a future article.

As a Software Engineer and Technical Team Lead, Oana Brezai designed and implemented solutions for clients in various industries such as retail, banking, insurance, automotive, public administration, and telecom. She is passionate about Information Retrieval and works mostly with open source tools, SOLR being one of them. In her free time, she is actively involved in a public speaking club.
Got a question or need advice? We're just one click away.